Spansion is a name that’s probably familiar to many of you, as a supplier of nonvolatile memories. You might be wondering, therefore, what the company’s doing gracing the pages of InsideDSP. Well, hold that thought! Spansion was originally founded in 1993 as a joint venture of AMD and Fujitsu, and named FASL (Fujitsu AMD Semiconductor Limited). AMD took over full control of FASL in 2003, renamed it Spansion LLC in 2004 and spun it out as a standalone corporate entity at the end of 2005.
Spansion’s product line is predominantly derived from a NOR flash memory foundation, in both serial and parallel interface device options, as well as including a comparatively limited number of NAND flash memories. NOR flash memory’s rapid random read speeds make it ideal for fast data fetch and direct code execution applications. Conversely, NOR tends to not be as dense (therefore cost-effective on a per-bit basis) as NAND on a comparable process technology, nor does it keep pace with NAND’s write speeds. Both factors hamper NOR’s ability to compete against NAND in bulk code and data storage applications. And Spansion also has plenty of NOR flash memory competitors in traditional application and customer strongholds.
Hence, the company is striving to diversify and differentiate itself, with a series of logic-enhanced devices that exploit NOR flash memory’s strengths while not being unduly hampered by its versus-NAND shortcomings. Spansion calls them Human Machine Interface Coprocessors, and the first one in the family, the Acoustic Coprocessor, targets speech recognition applications. Spansion’s product materials also sometimes incorrectly reference “voice recognition”; the two terms refer to different applications. The Acoustic Coprocessor focuses on the translation of spoken words (speech) into text; it’s not intended to uniquely authenticate or verify the identity of a speaker.
In defining the Acoustic Coprocessor via a partnership with Nuance, a well known voice technology developer, Spansion was guided by the observation that in conventional speech recognition algorithms, a substantial percentage of the total processing time is spent simply comparing each incoming phoneme (fundamental digitized speech “building block”) against a database of phonemes, striving to identify a closest match (Figure 1):
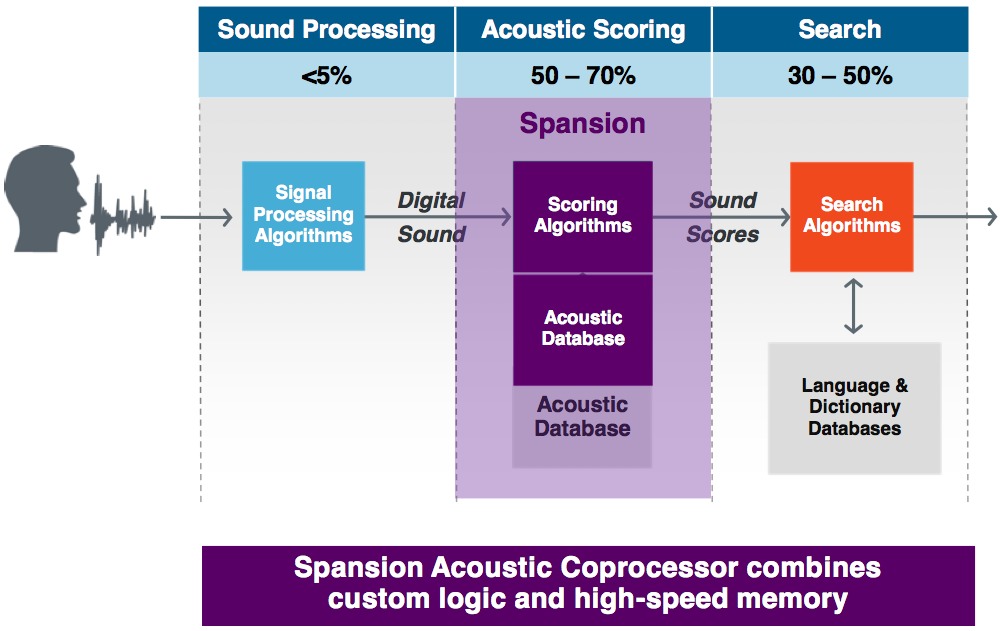
Figure 1. Upwards of 50% of the total time taken by a speech recognition algorithm can, according to Spansion and Nuance, be spent doing phoneme matching
Successive identified phonemes are then strung together by the voice recognition algorithm and transformed into words, using probabilistic calculations and other matching techniques. The Acoustic Coprocessor, as its name implies, is intended to offload the phoneme-matching portion of the algorithm from the CPU or DSP (Figure 2):
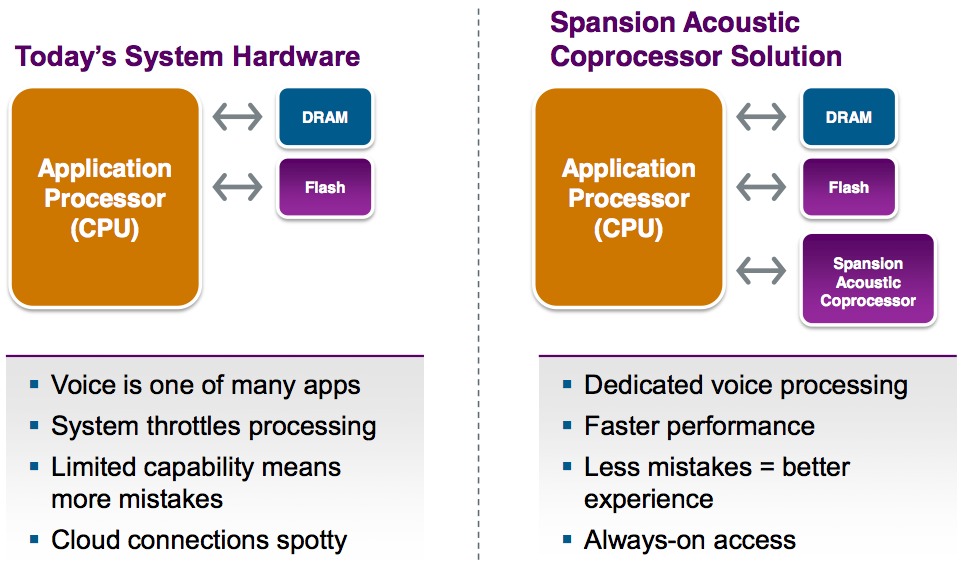
Figure 2. The Acoustic Coprocessor tackles the voice phoneme-matching function, thereby relieving the system CPU or DSP from this task
Think of the Acoustic Coprocessor as an application-optimized nonvolatile CAM (content-addressable memory). RAM-based CAMs have commonly found use in networking applications, as Wikipedia explains by case study example:
When a network switch receives a data frame from one of its ports, it updates an internal table with the frame’s source MAC address and the port it was received on. It then looks up the destination MAC address in the table to determine what port the frame needs to be forwarded to, and sends it out on that port.
The conventional software-based approach to implementing port forwarding employs a microprocessor, the flexibility of which is overkill for such a focused task, and which is also slower and more power-hungry than the CAM approach. Expand beyond the elementary switch to a more complex router, and the CAM’s superiority over a software-based implementation becomes even more apparent.
Similar CAM-like advantages apply to the Acoustic Coprocessor in speech recognition applications. The product combines the capabilities of a fast-access RAM and a nonvolatile phoneme storage device; the consequent two-memory function integration saves board space, power consumption and (potentially) cost. The phonemes are stored locally, versus being “cloud”-based, which enables speech recognition to continue to work even in settings where network data access is sketchy or nonexistent. And the Acoustic Coprocessor’s phoneme-matching response time, Spansion claims, is up to 50% faster than that which a conventional software-based approach can cost-effectively deliver.
The higher inherent performance of the Acoustic Coprocessor, Spansion and Nuance assert, can also be leveraged to improve voice recognition accuracy (Figure 3). The higher access speed of Spansion’s product enables larger phoneme tables, which could be used to enable more robust speech recognition by compensating for ambient noise and other factors that can confuse a more elementary implementation. In addition, larger phoneme tables can be used to enable recognition of multiple languages and dialects.
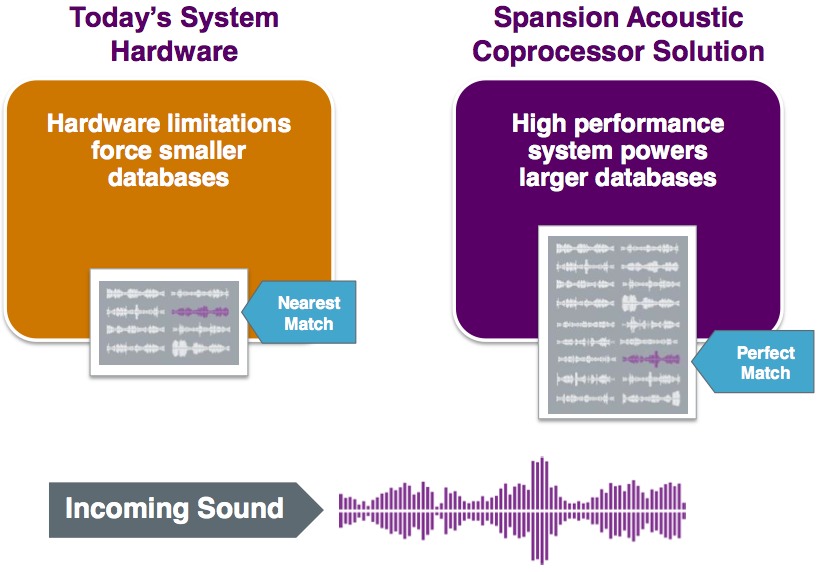
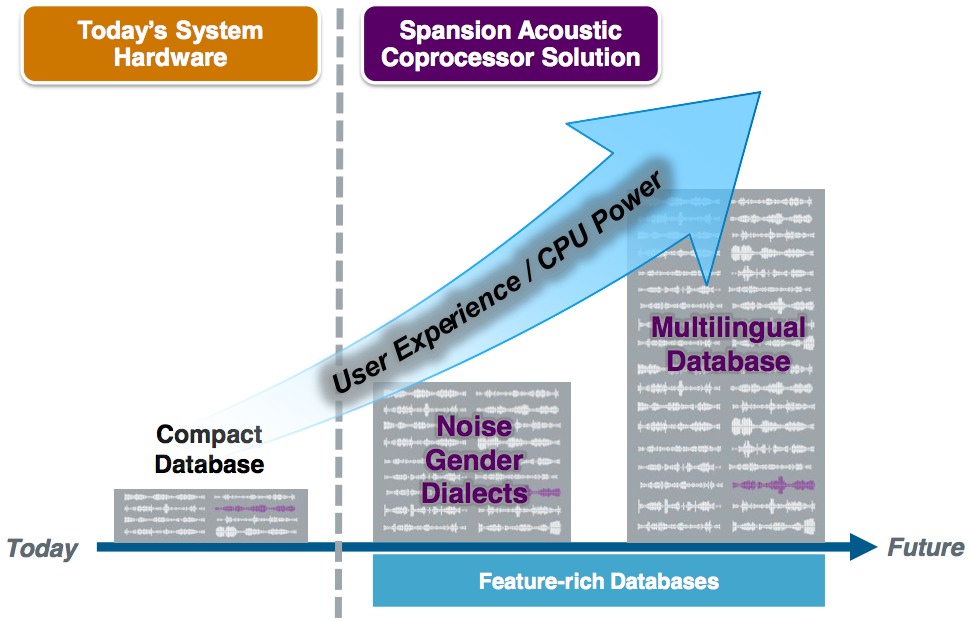
Figure 3. The Acoustic Coprocessor’s faster phoneme search-and-match speeds allow for larger phoneme tables (top graphic), which support incremental languages and dialects, along with user-specific voice recognition capabilities and ambient noise compensation (bottom graphic)
The larger phoneme database also allows for user customization, enabling the system to (for example) respond to the driver’s voice command to change the radio station while ignoring voices coming from vehicle passengers or from the radio itself, a desirable “focusing” feature that can also be enabled via directional microphones.
The 65 nm Spansion Acoustic Coprocessor is nearing tape-out, with initial sampling scheduled for the third quarter of this year and initial production slated for early next year. It will come in various flash memory capacities and also embeds “massively parallel” function-specialized search logic circuitry, with a 768-bit wide, 1.2 GByte/sec bus interconnecting the nonvolatile memory and logic blocks. With power consumption estimated at between 100 mW and 1.5 W depending on capacity and function, it’s not yet necessarily ready for battery-operated applications, but Spansion is already working with several large automotive manufacturers.
Spansion’s next-generation Acoustic Coprocessor aspirations encompass devices that offload from the CPU additional portions of various audio-processing algorithms. And Spansion also plans to expand beyond speech recognition into coprocessors for diverse embedded vision-based applications (Figure 4).

Figure 4. Speech recognition is Spansion’s initial Human Machine Interface Coprocessor focus, but vision-based applications such as face recognition, emotion discernment, gesture interfaces and advanced driver assistance are also on the company’s radar



